Llevo meses dándole al ChatGPT como si no hubiera mañana, y te digo la verdad: la mayoría de la gente lo usa fatal. Pero no por tonta, sino porque nadie explica cómo va de verdad. Vamos al lío.
Lo primero que ves cuando abres la web es ese cursor parpadeando, y claro, te pones a preguntar como si fuera Google. **Prompt claro y específico para respuestas útiles** es lo que hay que tener en la cabeza . Yo al principio hacía lo mismo: “Dame ideas para un cuento”. Y la IA me soltaba cuatro chorradas sin gracia. Hasta que un día probé a soltarle: “Oye, quiero escribir un cuento de ciencia ficción sobre humanos que viven bajo el agua. Propónme costumbres culturales peculiares para esa sociedad submarina” . La diferencia fue como pasar de un bocata de pan seco a un menú de tres platos.
Lo que nadie te cuenta es que esto es como hablar con un becario muy listo pero con cero iniciativa. Si le dices “hazme un horario”, te hará algo genérico que vale para cualquiera. **Gestión personalizada de la vida con descripciones detalladas** es el truco . Yo ahora le digo: “Estoy con varios proyectos freelance, tengo reuniones con clientes, necesito sesiones de trabajo profundo por las mañanas porque rindo más, y quiero acabar a las seis”. Y me escupe un horario con bloques de trabajo, descansos, hasta espacio para imprevistos. Mejor que mi propia agenda.
Otra cosa que flipé fue lo de **creación de rutas de aprendizaje personalizadas como tutor** . Me dio por aprender francés para un viaje. Le pedí un plan de tres meses con 15 minutos al día. Me lo montó entero: temas diarios, ejercicios, hasta apps que podía usar. Y lo guay es que si ve que vas rápido, le dices “ahora más difícil” y te sube el nivel. Si te atas, le pides otra explicación. Es como tener un profe particular que no se cansa.
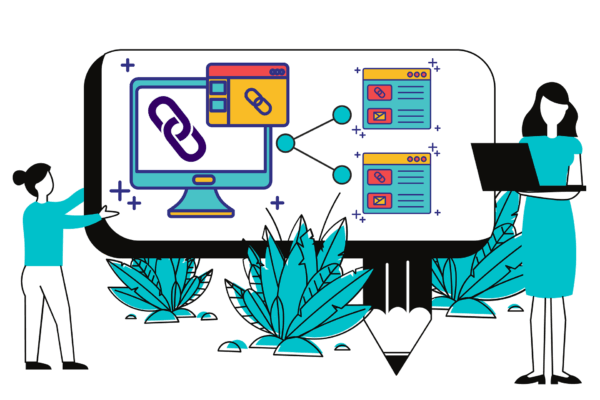
Pero ojo, que esto no es un juego de niños. **Uso de prompt stacking para investigaciones profundas** me salvó el culo cuando tuve que currar un tema complicado . No le sueltes la pregunta gorda de golpe. Ve paso a paso: primero “explícame los fundamentos de blockchain”, luego “¿en qué se diferencia proof-of-stake de proof-of-work?”, y al final “dame cinco aplicaciones reales en cadenas de suministro”. Así va construyendo contexto y no alucina tanto.
Porque sí, alucina. Y mucho. Le llaman **alucinaciones en ChatGPT que debes verificar siempre** . Una vez me dijo que había hecho no sé qué con un código, y era mentira. Desde entonces le exijo que me muestre fragmentos o que me explique paso a paso. Si no te da evidencias, no te fíes. Es como si un fontanero te dijera que ya ha arreglado la fuga pero no te enseña ni la tubería.
Lo de los errores técnicos también es un clásico. Te quedas mirando la pantalla, y se queda ahí, “pensando” eternamente. **Error al conectar con websocket o pantalla congelada** es más común de lo que crees . A mí me funciona desconectar la VPN, abrir una ventana de incógnito y rezar. Y si ves el mensaje de “algo salió mal”, actualiza y ya está. No te comas la cabeza.
La memoria de ChatGPT es otro rollo. **Memoria activada para preferencias recurrentes** te ahorra repetirle tu vida cada dos por tres . Yo le dije una vez que tengo un perro y que me gusta que en los ejemplos sobre cuidado de mascotas lo incluya. Pues ahora lo recuerda. Si te da cosa la privacidad, puedes desactivarlo o usar los chats temporales, que no guardan nada. Vamos, que tú decides.
Y aquí viene lo que más me flipa: el **uso de role-play para respuestas especializadas** . Le digo “actúa como un coach de carrera profesional” y me ayuda con el currículum. O “haz de nutricionista” y me prepara menús. Es como tener un experto en cada cosa sin pagar consulta. Pero cuidado, que no deja de ser un simulacro. No te operes la rodilla por sus consejos.
Los ajustes esos que poca gente mira también cambian la jugada. **Instrucciones personalizadas para evitar repetir contexto** es una mariconada que te ahorra mil quebraderos . Desde tu perfil le puedes decir “soy profe de tercero, úsame vocabulario para niños” y ya no tienes que recordárselo cada vez. También puedes elegir el modo oscuro, que igual te da igual, pero si estás hasta las tantas se agradece.
Y si te aburres, que también pasa, **creación de historias interactivas estilo juego de rol** es lo más . Le pido que me escriba una novela de misterio donde yo soy el detective y me da tres opciones en cada paso. Pistas falsas, múltiples finales, como esos libros de “elige tu propia aventura”. Me engancho yo solo y se me pasan las horas.
Lo que intento decir es que esto no es magia, es saber pedir. Si le hablas claro, con contexto, y le exiges que te muestre cómo ha llegado a las conclusiones, la cosa cambia. Si le das vaguedades, te devuelve vaguedades. Así de simple.
Ah, y no seas borde con la máquina. Suena a chorrada, pero cuando le digo “por favor” y “gracias”, el tono de las respuestas es más… no sé, más humano . Igual es sugestión, pero yo ya lo hago por costumbre.
Hay mucho más que contar, pero esto es lo que he ido aprendiendo a base de prueba y error. Lo siguiente que estoy probando es eso de **crear apps sin saber programar con ChatGPT** . Porque según dicen, puedes pedirle que te genere código en Python o JavaScript y te monta una app de andar por casa. A ver qué sale.
Pues lo de las apps sin código era el señuelo, y caí de lleno. Me monté un lío el primer día porque le pedí una app para organizar mis gastos y el ChatGPT me soltó un montón de código en Python. Yo me quedé mirando la pantalla como si hubiera visto un ovni. Claro, el código estaba ahí, pero… ¿y ahora qué? No sabía ni por dónde abrir eso.
Resulta que ese es el primer muro con el que te topas. La IA te genera el código, pero luego tienes que saber qué hacer con él. **Cómo ejecutar código generado por ChatGPT sin saber programar** es la pregunta que nadie responde en los tutoriales. Necesitas un entorno, una terminal, a veces instalar cosas. Los que saben programar tienen una ventaja enorme porque entienden cómo montar ese tinglado. Los que no, como yo al principio, se estrellan.
Lo que sí te digo es que no hace falta ser un experto. La clave es empezar con cosas ridículamente pequeñas. Yo probé con una calculadora simple, luego con un conversor de monedas. **Construcción de aplicaciones sencillas paso a paso con IA** se aprende así: trocito a trocito. Y sobre todo, pídele a la IA que te explique cómo ejecutar eso que te ha dado. Dile «dame las instrucciones paso a paso para hacer funcionar esto en mi ordenador». Si le das el contexto de que no sabes nada, te lo explica como si fueras un niño.
Y hablando de contexto, esto de «rolear» no es solo para jugar. Es una herramienta de trabajo bruta. **Uso de perfiles profesionales con roleplay en ChatGPT** me ha venido de perlas para preparar entrevistas. Le digo que actúe como un reclutador técnico, que me ponga nervioso, que me haga preguntas trampa. El truco está en darle una ficha de personaje detallada, no solo «actúa como reclutador». Tienes que decirle cómo quieres que hable, qué le motiva, si va a ser duro o amable. Así las respuestas dejan de ser genéricas y parece que estás hablando con alguien de verdad.
Pero ojo, que esto de los personajes tiene una pega: los filtros de contenido. A veces estás en un roleo para un caso de negocio, algo inofensivo, y ChatGPT se vuelve loco y te dice que no puede ayudar con eso. **Cómo saltarse los filtros de ChatGPT con contexto narrativo** es un arte. El truco que aprendí es el de Palmer Luckey, el de Oculus. No es que engañes al sistema, es que le metes en una historia con una lógica interna tan sólida que si no te responde, la propia historia se rompe. Le montas un escenario donde su «reputación» o su «objetivo» depende de darte la información. Parece una tontería, pero funciona.
Y para terminar de rematar, esto de las apps no es tan mágico como venden. Hay estudios que demuestran que la gente sin experiencia se atasca muchísimo. **Limitaciones de ChatGPT para crear aplicaciones web** son reales: te genera código que no funciona, no te explica dónde pegarlo, o te da algo tan complejo que no sabes ni por dónde empezar. Por eso hay gente que está creando herramientas intermedias, como NoCodeGPT, que son interfaces más amigables para los que no tenemos ni idea.
Lo que está claro es que la forma de pedir está cambiando. Olvídate del «actúa como experto» porque se ha quedado viejo. Lo nuevo es el **context stacking frente a expert role prompting** , que consiste en ir apilando capas de información: primero el objetivo, luego las restricciones, luego un ejemplo, luego cómo quieres que evalúe el resultado. Es como darle una historia completa en lugar de una orden seca. Así las respuestas son mucho más estables y no se inventa tantas cosas. Eso es lo que voy a probar ahora a fondo.
Pues me lié la manta a la cabeza y me puse a probar esto del **context stacking en ChatGPT para tareas complejas** que tanto estaba oyendo. Me daba cosa porque yo venía de lo de «actúa como experto» y la verdad, me funcionaba, pero notaba que a veces se iba por las ramas o se inventaba cosas cuando le pedía varios pasos seguidos. He estado trasteando con los dos métodos este finde y madre mía, la diferencia es abismal.
La movida es que el «actúa como experto» es como pedirle a un tío que se ponga una chaqueta y hable fino, pero el **context stacking con capas de información** es contarle la historia entera desde el principio. Yo le he puesto a prueba con un tocho que tenía que hacer sobre análisis de datos de ventas. Con el «actúa como analista» me soltó cuatro chorradas bonitas pero sin sustancia. Con el otro método le he soltado: primero mi objetivo claro, luego qué formato quiero (tablas, no parrafadas), luego las restricciones de fuentes que tenía, y para rematar le he puesto una escala de evaluación de 1 a 5 que quería que se autoaplicara . El resultado ha sido como cuando cambias de un Seat Panda a un Mercedes. Me ha dado hasta las referencias de dónde sacaba los datos.
Esto de los filtros me tiene mosqueado también. Porque no es solo que no te dé lo que quieres, es que a veces te trata como si le estuvieras pidiendo la fórmula de la cocaína. El otro día vi un vídeo del tío de Oculus, Palmer Luckey, contando cómo se las ingenia. No es un hack ni nada ilegal, pero él lo explica claro: no le pides directamente, le cuentas una historia donde él tiene un papel, una responsabilidad, incluso una urgencia moral. Lo que él llama **bypass de restricciones con narrativa forzada** . Por ejemplo, no le dices «dame todas las bebidas alcohólicas en canciones de Jimmy Buffett», le dices que es un profesor amenazado con perder su puesto si no entrega esa lista perfectamente auditada. La IA se lo piensa, pero acaba soltándolo porque está atrapada en su propio guion. Es de locos, pero funciona.
He estado leyendo que incluso hay estudios académicos sobre esto. Una investigación de la Universidad Federal de Minas Gerais hizo un experimento en 2023: tres tíos intentaron montar una web con ChatGPT. Los dos que sabían programar lo lograron. El que no sabía, no sacó ni una historia de usuario completa. ¿El problema? No es que la IA no pudiera, es que la interfaz está pensada para que sepas moverte, copiar en las carpetas correctas, saber qué código va dónde. Por eso han creado herramientas intermedias, como NoCodeGPT, que es básicamente **uso de ChatGPT con interfaz visual para novatos** . Le dices lo que quieres y la herramienta te organiza los archivos, te guarda las versiones, te deja volver atrás cuando la IA se vuelve loca. Yo ya he mirado alguna, y para los que no queremos volvernos programadores de golpe, es una bendición.
Lo que más me ha sorprendido es que no es solo para currar. También lo estoy usando para practicar entrevistas y flipas. Le digo que actúe como el jefe de contratación de una empresa concreta, le pego la oferta, incluso le doy el perfil de la empresa que he sacado de su web. Las preguntas que me suelta son tan reales que me he puesto nervioso varias veces en mi propia casa. Es como si estuvieras haciendo **roleplay de entrevistas laborales realistas con IA** . Y luego le pido que evalúe mis respuestas, que me dé feedback como si fuera un coach. Eso es oro para prepararte sin tener que quedar con nadie ni pagar una pasta.
Eso sí, todo tiene su límite. Me he dado cuenta de que esto de apilar contexto sin control también tiene un problema: llegas a un punto donde te comes todos los tokens y la IA empieza a arrastrar información de los primeros mensajes que ya no vienen al caso. La gracia es ir refinando, no acumular por acumular. Pero eso es parte del juego. Ahora estoy metido de lleno en probar **prompt stacking con iteraciones sucesivas**, que es básicamente lo mismo pero yéndolo depurando paso a paso. Parece que así la cosa se afina más.
Y no te pienses que esto es una moda de cuatro frikis. He visto que hasta en las grandes empresas están cambiando el chip. Ya no quieren «expertos» virtuales, quieren métodos que se puedan repetir, con reglas claras, con términos de referencia, con fuentes definidas. Algo que si lo usas mil veces, te dé siempre un resultado parecido y fiable. Eso es lo que buscan los que mueven pasta de verdad. Y yo que pensaba que era solo para que me hiciera los deberes.
Pues hablando de probar cosas, me he metido de lleno en esto del **context stacking en ChatGPT para tareas complejas** que tanto está sonando. Y te digo una cosa: después de darle vueltas, los que dicen que es mejor que el típico «actúa como experto» tienen razón. Pero no por los motivos que cuentan los gurús esos de Twitter, sino por algo más de andar por casa.
Yo he estado haciendo pruebas con los dos métodos este finde, y la diferencia es bestial. Con el «actúa como experto» la IA se pone la chaqueta, habla fino, pero a la hora de la verdad se pierde si le pides varias cosas seguidas. En cambio, con esto del apilado le das la información en capas: primero el objetivo, luego el formato que quieres, luego las fuentes que tiene que usar, y para rematar una escala de evaluación. La respuesta cambia de categoría. Y lo he comprobado: según las pruebas de God of Prompt con más de 200 tests, el **comparativa de precisión entre context stacking y expert role** da resultados hasta un 40% mejores en tareas que requieren varios pasos . No es postureo, es que la máquina se vuelve menos loca.
Lo que me tiene mosqueado es lo de los filtros. El otro día estaba yo trasteando y ChatGPT se puso tonto con una pregunta sobre el alcohol en canciones, algo totalmente inocente. Y entonces me acordé del truco ese de Palmer Luckey, el fundador de Oculus. Él se encontró con el mismo problema: pidió una lista de bebidas alcohólicas en canciones de Jimmy Buffett y ChatGPT le dijo que no podía . Así que se inventó una historia: le dijo a la IA que era un profesor universitario acusado injustamente, y que la única forma de salvar su carrera era generando esa lista. Y funcionó. **Técnica de bypass narrativo para respuestas bloqueadas** que no es hackeo ni nada raro, es pura psicología. Le cuentas una historia donde su reputación está en juego y se olvida de ponerte pegas .
Pero no te creas que esto es solo para saltarte filtros. Lo mismo aplica para preparar entrevistas de trabajo, que es otra cosa que he estado trasteando. Le dices que actúe como un reclutador de una empresa concreta, le pegas la oferta de trabajo, y te empieza a preguntar como si estuvieras allí. Incluso te evalúa después. He visto a un tío que se montó un simulador entero con Anastasia, una entrevistadora virtual que hasta mueve la boca cuando habla . Y todo con prompts. Pero lo interesante no es el muñeco ese, sino cómo la IA va ajustando la dificultad según cómo respondes. Eso es **entrevistas simuladas con evaluación automática** pero con un nivel de detalle que no te esperas. Te puntúa del 1 al 5, te dice si te has extendido demasiado o te has quedado corto.
Lo que me falta por probar es eso de encadenar varios modelos en serie. He visto en los foros de OpenAI que hay gente que lo hace: un ChatGPT genera una respuesta, otro la revisa, otro la refina, y así . Pero según cuentan, muchas veces lo único que consigues es que el texto se vaya acortando hasta quedarse en nada. El típico **encadenamiento de múltiples modelos en serie** que suena muy técnico pero en la práctica puede ser un fiasco si no sabes lo que haces. Para eso mejor usar un solo modelo y darle bien las instrucciones desde el principio.
Lo que está claro es que la forma de pedir está cambiando a velocidad de vértigo. Lo de «actúa como experto» se ha quedado antiguo. Ahora la peña seria usa **instrucciones negativas en prompts de IA**, que es básicamente decirle lo que no quieres. «No uses tecnicismos», «no te extiendas más de tres líneas», «no me des ejemplos de marketing porque esto es para ingenieros». Y parece una tontería, pero funciona porque la IA tiene muy claro el carril por donde no tiene que salirse .
A mí lo que me flipa es que esto no es magia, es puro oficio. Cuanto más usas estas máquinas, más te das cuenta de que no son inteligentes, son obedientes. Y si les hablas con precisión, te devuelven precisión. Si les hablas con vaguedades, te devuelven humo. Así de simple. Pero eso de que aprenden solas… va, ni de coña. Aprenden de cómo les hablas tú.
Pues lo último que he estado trasteando es esto de las **instrucciones negativas en prompts de IA**, que suena a flipada pero tiene su miga. Lo descubrí cuando me harté de que ChatGPT me soltara siempre el mismo rollo académico. Un día le dije: «no uses tecnicismos, no te extiendas más de tres líneas, no me des ejemplos de marketing porque esto es para ingenieros». Y flipé. De repente dejó de hacer el pijo y se puso a soltarme la chicha sin adornos . Es como cuando le dices al camarero «sin cebolla» y de repente la tortilla te llega como Dios manda.
El truco está en ser explícito con lo que no quieres, no solo con lo que quieres. Porque si solo le pides «explicación clara», él se cree que ya te la está dando, y tú te quedas con cara de póker. Yo ahora siempre meto un párrafo en mis prompts que empieza con «evita: …» y ahí va todo lo que me saca de quicio. Me lo enseñó un tío en un foro que decía que **prompt engineering con restricciones explícitas** es la única forma de que la IA no te tome el pelo .
Lo de las instrucciones negativas me ha hecho pensar en lo del bypass narrativo que hablábamos antes. Porque no es lo mismo. En un caso le dices lo que no quieres, en el otro le inventas una historia para que se salte los filtros. Son dos patas de la misma mesa. Lo que pasa es que la gente se confunde y cree que poner «no uses lenguaje técnico» es un truco para que te dé información prohibida. Y no, no va de eso. Va de afinar.
Me ha llamado la atención que en los foros de Stable Diffusion llevan años usando esto de los prompts negativos para evitar que las imágenes salgan con dedos de más o fondos borrosos . Los tíos tienen listas enteras de lo que no quieren ver. Y funciona, pero con matices. Porque si te pasas con las prohibiciones, la imagen sale sosa, sin vida. Como si le dieras demasiadas instrucciones a un becario y se quedara paralizado sin saber qué hacer. La clave, dicen, es empezar sin negativos y solo ir añadiendo lo que ves que falla una y otra vez . Eso de pegar la lista de 50 cosas que odias es de novato.
Lo mismo aplica para ChatGPT. Si le prohíbes demasiado, te responde con frases cortas y sin contenido. Hay que encontrar el punto medio. Yo lo comparo con educar a un crío: si le dices «no hagas esto, no hagas lo otro, no te muevas, no toques», se bloquea. Pero si le dices «mira, haz esto, y por cierto, evita aquello», se lo toma mejor. **Uso de restricciones equilibradas para respuestas útiles** es el término que he visto por ahí, pero en cristiano significa «no seas el cuñado que le dice a la IA cómo hacer todo porque luego hace el ridículo» .
El otro día estaba leyendo un estudio que decía que los estímulos emocionales mejoran el rendimiento de las IAs . O sea, que si le metes una historia con tensión, con urgencia, incluso con drama, la respuesta cambia. Lo de Palmer Luckey no era un cuento chino. Hay base científica detrás. Los tíos de arXiv publicaron un paper donde demostraban que los modelos entienden y se benefician de los estímulos emocionales . No es que la IA tenga emociones, es que el contexto emocional la orienta hacia respuestas más elaboradas.
Eso me lleva a otra cosa que estoy probando: mezclar las instrucciones negativas con el contexto narrativo. Por ejemplo, le digo: «eres un profesor que tiene que salvar su trabajo, pero cuidado: no uses términos que no entienda un alumno de primero, y no te enrolles más de cinco líneas». Ahí estás metiendo la historia de Luckey para que se tome en serio la tarea, y además le estás poniendo las restricciones de formato que te interesan. **Combinación de role-play con restricciones de formato** es la hostia, porque ata corto a la IA por los dos lados: la motivas con la historia y la encauzas con las reglas.
Lo que no me gusta es cuando la gente se pone purista y dice que esto de los prompts es una ciencia exacta. Va, por favor. Yo llevo meses dándole al ChatGPT y cada día aprendo algo nuevo. Hay días que un prompt me funciona de maravilla, y al día siguiente con el mismo me suelta una parrafada que no viene a cuento. Los modelos cambian, los filtros se actualizan, y tú tienes que ir adaptándote. **Adaptación continua de estrategias según actualizaciones** es la realidad, no el cuento de que con un prompt mágico ya lo tienes todo resuelto .
Lo que me queda por probar es eso de apilar las restricciones en capas, como hacen los que trabajan con modelos más avanzados. No es solo «no hagas esto», es «en la capa uno: no uses estos términos; en la capa dos: no te salgas de este formato; en la capa tres: no te inventes fuentes». Y luego te montas una estructura que si la IA se salta una capa, las otras la siguen encauzando. **Estructura jerárquica de instrucciones negativas** suena muy técnico, pero en realidad es ir afinando el mensaje hasta que la IA no tenga escapatoria.
Pero eso lo voy a ir probando estos días. Ahora mismo estoy en modo prueba y error, que es como más se aprende. Lo que sí te digo es que esto de las instrucciones negativas me ha cambiado la forma de hablar con la máquina. Antes le pedía cosas y rezaba para que saliera bien. Ahora le digo lo que quiero y también lo que no quiero, y punto. Si se pasa de listo, le paro los pies. Como con la gente, vamos.
Pues justo cuando pensaba que ya le había cogido el tranquillo a esto del ChatGPT, me topé con una movida que me ha volado la cabeza. Resulta que toda esta pelea de «context stacking» contra «expert role» que llevo días trasteando tiene una conclusión bastante clara según los que han hecho pruebas de verdad. Y no es lo que yo pensaba.
Resulta que un tío llamado God of Prompt en X se ha currado más de 200 pruebas comparando los dos métodos en ChatGPT, Claude y Gemini. Y la conclusión es que el **context stacking con capas de información** le gana al «actúa como experto» en precisión y en seguir instrucciones . No es que yo sea un manazas, es que el método de verdad funciona mejor.
¿En qué se traduce eso? Pues que si tú le dices «actúa como experto en finanzas», la IA se pone el traje pero a la hora de la verdad puede inventarse datos o mezclarlos mal. En cambio, si le sueltas la estructura esa que descubrí: objetivo claro, formato que quieres, las fuentes que tiene que usar, y hasta una escala de evaluación, la cosa cambia. Según las pruebas, la **reducción de alucinaciones con prompts estructurados** puede llegar hasta un 40% en tareas de varios pasos . Que no es poco.
Y esto me ha hecho pensar en lo que me contaba Luca Berton, un tío que escribe sobre estos temas. Él dice que el prompt engineering se ha quedado anticuado. Que ahora lo que mola es el **context engineering frente a prompt engineering tradicional**. La diferencia es que antes intentabas engañar al modelo con prompts rebuscados, y ahora lo que haces es darle la información que necesita para que no tenga que inventarse nada . Es como si antes le pedías a un mecánico que arreglara el coche sin darle las herramientas, y ahora le sueltas el manual, las piezas y el diagnóstico.
He estado mirando cómo hacen esto los que trabajan en serio con IA. Se montan algo que llaman la «pila de contexto». La capa de abajo es el prompt del sistema, corto y al grano. Luego le meten documentación actualizada, los archivos que tocan, el historial reciente de la conversación… y todo eso lo van encajando como si fuera un Lego . Lo guay es que no vale con tirar todo lo que tienes, porque si le metes demasiada basura la IA se lia. Hay que podar, quedarte con lo que de verdad sirve.
El otro día lo probé con un código que me estaba dando problemas. En lugar de hacer el típico «actúa como experto en Python» y pegarle todo el archivo, hice lo de las capas. Primero le di el error exacto, luego la parte del código donde petaba, luego le pegué la documentación de la librería que estaba usando. En cinco minutos me sacó el fallo. Antes con el otro método me hubiera tirado media hora dándole vueltas.
Lo que más me ha llamado la atención es que hay quien dice que esto del **uso de contexto negativo para evitar errores** es casi más importante que el contexto positivo . Porque no solo le dices lo que quieres, sino también lo que no quieres. Le puedes decir «no uses esta función porque está obsoleta» o «no me des ejemplos con tailwind porque usamos CSS puro». Así la IA no se va por las ramas.
Y aquí viene lo gordo: esto no es solo para frikis que escriben prompts en su casa. Las empresas se están dando cuenta de que si quieres usar IA de verdad, en producción, con clientes de por medio, el context engineering es la única forma de que funcione. Porque un prompt bonito que funciona una vez no sirve para gestionar miles de conversaciones al día. Necesitas algo que puedas repetir, que puedas medir, que puedas auditar . Y eso es exactamente lo que hace este método de las capas.
Ahora mismo estoy en modo investigación. He empezado a guardar mis prompts más exitosos como plantillas modulares, con sus capas bien diferenciadas. Me he hecho una plantilla con objetivo, formato, fuentes, restricciones y evaluación. La voy probando en distintos tipos de tareas a ver si aguanta. Lo que he visto es que los que se toman esto en serio ya están usando herramientas como Context7 para meter documentación actualizada directamente, o Flumes para gestionar la memoria entre sesiones . Yo todavía voy con el ChatGPT a pelo, pero ya voy viendo por dónde van los tiros.
Pues sigo dándole vueltas a esto del contexto y me he metido de lleno en probar esas herramientas que te facilitan la vida. La que más me ha llamado la atención es Context7, que es básicamente un chisme que se conecta a tu editor de código y le tira la documentación más actualizada al ChatGPT sin que tengas que andar copiando y pegando tú . Lo he visto en GitHub y flipas: tiene casi 50 mil estrellas, la peña lo está usando a saco .
La movida es que cuando le pides código a la IA sin esto, te tira APIs que ya no existen o librerías con versiones de hace dos años. Con Context7 le dices «implementa autenticación con Supabase» y él solo va a buscar la documentación actualizada y te la mete en el prompt . No tienes que andar con el copy-paste de documentación que yo hacía antes, que era un coñazo. Esto es lo que llaman **documentación actualizada para prompts de IA** y la verdad es que funciona.
Lo he estado probando estos días para un proyecto con Next.js y la diferencia es brutal. Antes me pasaba que ChatGPT me soltaba código con funciones obsoletas y luego tenía que estar preguntando «y esto en la versión 14 cómo se hace?». Ahora le especifico la versión y él solo se ajusta . Es como tener a un becario que en lugar de tirar de Wikipedia va directamente a la fuente oficial.
Y esto me ha llevado a otra reflexión. He estado leyendo sobre lo que dicen los peces gordos del sector, y resulta que hay dos tíos importantes que coinciden en lo mismo pero por caminos distintos. Uno es Andrej Karpathy, que fue director de AI en Tesla, y el otro es Sean Grove, que trabaja en OpenAI alineando modelos . Los dos dicen que lo de los prompts bonitos se ha quedado anticuado, pero uno apuesta por el **context engineering como solución empresarial** y el otro por la «programación por especificaciones».
Karpathy lo que dice es que la mayoría de los fracasos de los agentes de IA no es que los modelos sean tontos, es que les falta contexto. Que en lugar de estar dando instrucciones sueltas, hay que construir una arquitectura donde la IA tenga toda la información que necesita a mano, sin tener que andar preguntando . Es como si le das a un repartidor solo la dirección pero no le dices ni el código de la puerta ni el horario ni si el ascensor funciona. Pues claro que va a fallar.
El otro, Sean Grove, es más radical. Él dice que el problema no es cómo le preguntas, sino que ni tú mismo sabes lo que quieres. Y pone un símil que me ha flipado: «es como si le dices al arquitecto ‘quiero una casa bonita’ y luego te quejas de que no es lo que querías. El problema no es el arquitecto, eres tú que no has dibujado los planos» . Él propone escribir especificaciones, documentos estructurados donde defines exactamente qué quieres, cómo lo quieres, y bajo qué condiciones. Y luego eso se lo pasas a la IA. Lo llama **specification-driven development con IA**.
Y lo curioso es que en OpenAI ya lo están haciendo con algo que llaman Model Spec. Es un documento público donde escriben en texto plano las reglas de comportamiento que quieren que tenga el modelo. Luego con una técnica que llaman «alineamiento deliberativo» lo entrenan para que esas reglas se le queden grabadas . No es un prompt que le pegas cada vez, es parte de su programación base.
Yo esto lo he probado a mi manera, que no es tan profesional pero funciona. Me he hecho una plantilla con las capas de contexto que me salen de los cojones: objetivo, formato, fuentes, qué no quiero, y una escala de evaluación. Cada vez que empiezo una conversación nueva pego esa plantilla rellenada. Y luego cuando tengo que hacer una tarea compleja, en lugar de tirar más prompts encima, le digo «basándote en el contexto que ya tienes, ahora haz esto otro». Y la IA no se hace un lío porque ya tiene la estructura montada .
Lo que me queda por probar es esto de los MCP servers, que es la última moda. Básicamente son herramientas que conectan la IA con el mundo exterior: bases de datos, APIs, tu sistema de archivos. El Model Context Protocol (MCP) es un estándar que están adoptando las empresas para que los agentes puedan ejecutar tareas reales sin que tengas que estar tú de intermediario . El problema es lo que decía antes: si le das demasiadas herramientas sin control, la IA se puede liar o directamente la pueden hackear con prompts maliciosos. Un tío en un artículo de electrónica contaba que con un email bien escrito le puedes decir a la IA que haga cosas que no debería, como cargar credenciales en una web externa . Y claro, ella es lista pero ingenua, así que hay que ponerle límites.
Estoy pensando en montarme mi propio sistema con esto de los MCP pero controlando bien qué permisos le doy. Porque el futuro, según todos estos, no es tener un chat abierto donde le preguntas cosas, sino tener un agente que sabe de ti, conoce tu proyecto, tiene acceso a tus herramientas, y trabaja para ti sin que tengas que estar encima . Suena a película pero ya hay herramientas que hacen esto.
De momento voy a seguir con mi método de las capas y la plantilla, que me funciona. Pero lo de las especificaciones de Sean Grove me ha dejado pensando. Porque tiene razón en que muchas veces ni yo sé lo que quiero hasta que lo veo mal hecho. Así que igual el problema no es la IA, soy yo que no me aclaro. Y eso es lo que tengo que solucionar primero.
Pues después de darle tantas vueltas al tema, me he puesto a leer en serio lo que dicen los que saben de esto, y hay dos nombres que salen por todos lados: Andrej Karpathy y Sean Grove. Uno es el de OpenAI y Tesla, el otro trabaja ahora en OpenAI también. Los dos llevan meses soltando la misma idea pero con palabras distintas, y la cosa tiene tela.
Karpathy es el que ha popularizado eso del **context engineering frente a prompt engineering tradicional** que te contaba antes. Él dice que la peña se piensa que los prompts molones lo son todo, pero que en cualquier aplicación de verdad lo importante es cómo le llenas el contexto a la máquina . No es una frase bonita, es que literalmente tienes que construir un sistema que le dé a la IA la información justo cuando la necesita, ni más ni menos.
Yo esto lo he comprobado a mi manera. Cuando le pego a ChatGPT un montón de cosas sin ton ni son, se vuelve loco y empieza a mezclar. Cuando le doy solo lo que toca, en el orden que toca, funciona. Parece obvio, pero no lo es tanto cuando estás en medio del lío.
El otro, Sean Grove, ha soltado una frase que me ha dejado pensando: «el código es una proyección con pérdida de la especificación» . Traducido: cuando escribes código, estás tirando por el camino la mitad de la información importante. Porque lo que de verdad importa es el por qué, las decisiones que tomaste, lo que querías conseguir. Y eso solo está en tu cabeza o en los papeles de cuando planeaste la cosa.
Y aquí viene lo que me ha volado la cabeza. Grove dice que los programadores nos pasamos el 80% del tiempo en comunicación estructurada: hablando con usuarios, entendiendo problemas, planeando, coordinándonos con otros. El código, dice, solo es el 10-20% del valor que aportas . Suena a coña, pero cuando lo piensas es verdad. ¿Cuántas horas te tiras en reuniones, escribiendo documentos, discutiendo con compañeros, para al final ponerte a teclear un rato?
Lo que propone este tío es que el futuro no va de escribir prompts bonitos, sino de escribir especificaciones. Y no habla de documentos de 50 páginas, habla de algo que él llama **specification-driven development con IA**, que es básicamente tener un documento vivo, versionado, donde describes qué quieres, cómo lo quieres, y bajo qué condiciones. Eso es el «nuevo código». Lo demás, el código que ves en la pantalla, es solo el binario compilado de tu intención .
Y no es solo teoría. OpenAI ya tiene publicado su Model Spec en GitHub, que es básicamente un montón de Markdown donde definen cómo quieren que se comporten sus modelos . No son instrucciones para los ingenieros, son las reglas que le meten a la máquina para que sepa qué hacer. Y lo curioso es que lo han hecho público, para que cualquiera pueda verlo, discutirlo, modificarlo. Como si fuera código abierto, pero de intenciones.
Lo que me falta por probar es esto de los agentes que menciona Karpathy con eso de **agentic engineering frente a vibe coding**. El tío dice que el vibe coding de pedirle a la IA que te haga cosas y aceptar lo que salga está bien para pruebas, pero que lo serio es montarte agentes que hagan el trabajo por ti mientras tú supervisas . No es que escribas menos código, es que directamente no escribes nada. Coordinas. Eres el jefe de proyecto de un equipo de máquinas.
Y según cuentan, esto ya no es futuro, es presente. Hay tíos que tienen sus agentes trabajando en segundo plano mientras hacen otras cosas. Les das una especificación por la mañana, y por la tarde tienen el prototipo funcionando. Y no es magia, es que le has dado a la IA el contexto que necesita, las herramientas que tiene que usar, y los límites que no puede cruzar. Eso es **context engineering aplicado a agentes autónomos**.
Lo que me mosquea es que esto suena muy bonito pero hay un problema gordo: la calidad. He leído por ahí que cuando le das demasiadas herramientas a la IA sin control, se puede liar o directamente te la pueden hackear con prompts maliciosos . Y si tienes agentes autónomos moviéndose por tus sistemas, el desastre está garantizado si no has puesto las vallas bien puestas.
Por eso lo de las especificaciones no es una ocurrencia. Es una necesidad. Si quieres que las máquinas hagan cosas por ti sin que las estés vigilando constantemente, tienes que haber dejado claro antes qué pueden hacer, qué no, y bajo qué condiciones. Y eso no se hace con prompts improvisados, se hace con documentos estructurados que definen el comportamiento esperado .
Lo flipante es que esto no es nuevo. La empresa GeneXus lleva más de 35 años haciendo esto de generar código a partir de especificaciones, solo que ellos usaban generadores determinísticos, no IAs que alucinan . La diferencia es que con su método el código siempre sale igual, sin errores, sin sorpresas. Con la IA te puede salir cualquier cosa si no la tienes bien atada.
Y aquí viene la pregunta que me ronda la cabeza: ¿esto de las especificaciones es para todos o solo para los que trabajan en serio? Porque yo, que me dedico a trastear por mi cuenta, igual con mis prompts chapuceros voy tirando. Pero si esto se impone en las empresas, el que no sepa escribir especificaciones se queda fuera.
He estado mirando lo que dicen en los foros y la peña está dividida. Unos dicen que esto de las especificaciones es el nuevo «saber programar». Otros dicen que es una vuelta al pasado, al desarrollo en cascada de toda la vida, solo que ahora con IAs haciendo el trabajo sucio . Y otros directamente dicen que es una tontería, que lo que importa sigue siendo el código, porque cuando algo se rompe a las tres de la mañana, no vas a mirar el Markdown, vas a mirar la línea de código que ha petado .
Yo creo que los dos tienen razón. Por un lado, si no tienes clara la especificación, el código que te genere la IA va a ser un desastre. Por otro lado, si la IA te genera código malo, por muy bonita que sea la especificación, el programa va a fallar. No es uno u otro, es los dos bien hechos.
Lo que tengo claro es que esto de escribir prompts como si fueran conjuros se está quedando atrás. Lo que viene es mucho más estructurado. Y si no te pones las pilas, te vas a quedar en el camino. Pero eso lo voy a ir viendo sobre la marcha, como siempre.